Incident Monitoring Detect
Diagnose, and Resolve Faster
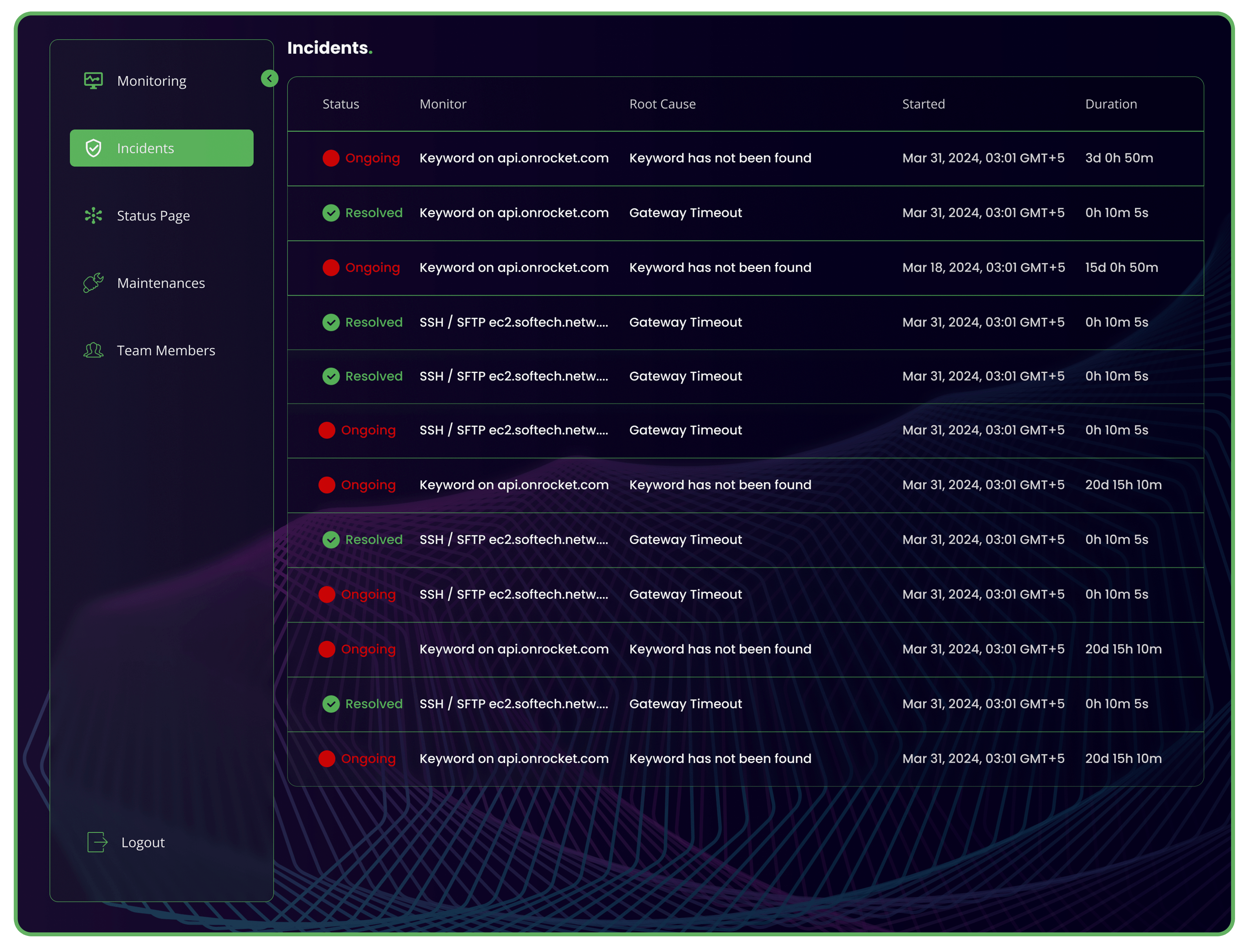
Incident Intelligence Forensic
Visibility Into Every Outage
PingForce doesn’t just alert you to problems—it delivers Incident Monitoring with forensic intelligence to dissect them. Our monitoring reconstructs failures minute-by-minute across your entire stack, with multi-location verification and AI-prioritized root causes. Stop guessing why systems broke—start knowing exactly how to fix them faster.
Failure Replay Technology
Watch exactly how an outage unfolded with timestamped snapshots of latency spikes, packet loss, and error codes—like a DVR for disasters.
Crowdsourced Incident Validation
When your server fails, we cross-check it against PingForce’s distributed monitoring nodes to confirm if it’s your infrastructure or a wider outage.
Blame Assignment Engine
Our system auto-tags probable culprits—SSL certs, DNS, your code, or third-party APIs—acting as automated incident management tools to fast-track resolution.
Silent Incident Detection
Find stealth degradations most tools miss—powered by incident management software that detects failures beyond basic alerts.
In-Depth Analysis
Clearly see failed during an outage—which regions, protocols, or endpoints stayed up—to pinpoint weak links in your architecture.
War Room Mode
One click generates a shareable incident cockpit with real-time graphs, impacted users, and recovery progress for team crisis calls.
Stop Wasting 68% of Your Outage Time on Diagnosis
The average team spends 41 minutes just finding the root cause of failures. PingForce’s blame assignment engine reveals the culprit in under 90 seconds—so you can fix what matters.
Stop Wasting 68% of Your Outage Time on Diagnosis
The average team spends 41 minutes just finding the root cause of failures. PingForce's Incident Monitoring engine reveals the culprit in under 90 seconds—so you can fix what matters without digging through logs.
Why PingForce's Incident Monitoring is Unmatched
Other tools show you when systems fail — PingForce combines Incident Monitoring with advanced incident management software to show you why they failed and how to prevent repeat outages. We transform raw alerts into actionable intelligence with military-grade precision, giving you an unfair advantage in outage prevention.
Failure Fingerprinting Technology
Our system creates a unique DNA profile for each incident type, automatically recognizing repeat offenders before they escalate into full outages.
Time-Machine Debugging
Scroll backward through second-by-second telemetry during crashes – like a black box recorder for IT disasters.
Crowd-Verified Outage Confirmation
We validate alerts across PingForce’s distributed monitoring nodes and community reports to cut false positives.
Predictive Incident Forecasting
Our algorithms analyze micro-patterns to warn about failures 15–30 minutes before they occur – like a weather radar for systems.
Multi-Cloud Postmortem Automation
Automatically generate audit-ready reports with root cause analysis, impact timelines, and corrective actions.
War Room Command Center
Launch a real-time collaboration hub during crises with system diagrams, chat, and automated playbooks.
What People Say About PingForce?
Outstanding Support
PingForce spotted a recurring database issue we'd been chasing for weeks. Fixed it in one afternoon.
Outstanding Support
The time-machine feature saved us 12 hours of debugging last month alone. Worth every penny."
Outstanding Support
We've cut our incident response time in half since switching. Our customers actually noticed the difference.
Your Monitoring Tool is Lying to You About 'Minor' Issues
Your Monitoring Tool is Lying to You About 'Minor' Issues
83% of stealth degradations (slow APIs, wrong data responses) go undetected for days. Our Silent Incident Detection exposes them immediately — doing what traditional incident management tools miss.
Frequently Asked Questions (FAQs)
We cross-verify every incident across PingForce’s distributed monitoring nodes and apply smart thresholds to filter out noise.
Yes. Our analytics dashboard automatically detects patterns in past incidents and predicts potential future failures before they happen.
Premium+ plans catch failures in under 60 seconds, with instant SMS/email alerts. Standard plans check every 5 minutes.
Absolutely. We track external dependencies and alert you if APIs, CDNs, or cloud services degrade or go down.
Yes. Set up custom notification rules for different roles—engineers get SMS, managers get email digests
Our AI analyzes error patterns and automatically groups similar incidents, helping you spot chronic issues faster.
Yes. We connect with Slack, PagerDuty, and other platforms via webhooks and APIs for seamless workflows.
War Room Mode activates automatically, giving your team shared dashboards, live logs, and recovery checklists.
All data is kept for 12+ months with full searchability. Export reports anytime for audits or reviews.
Try our free tier with distributed monitoring nodes — no credit card required. See the difference in your first outage.